目录
- HashMap的数据结构
- HashMap的工作原理
- 当两个对象的hashcode相同会怎样?
- JDK源码中HashMap的hash方法原理
- 为什么HashMap的数组长度要为2的n次幂?
- HashMap的table的容量如何确定?loadFactor是什么?该容量如何变化?
1、HashMap的数据结构
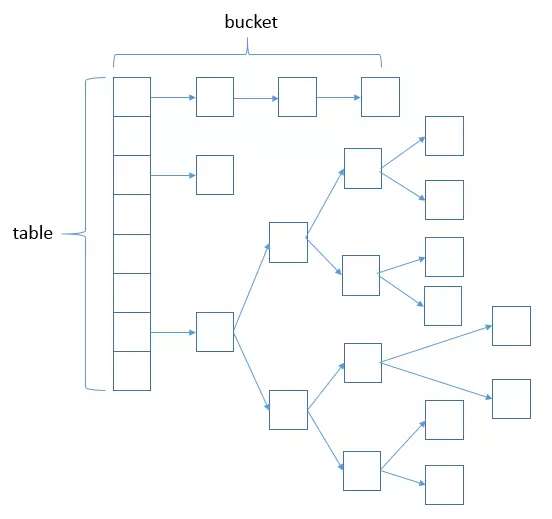
哈希表结构(链表散列:数组+链表)实现,结合了数组和链表的优点。当链表的长度超过8时,链表转换为红黑树(JDK8)
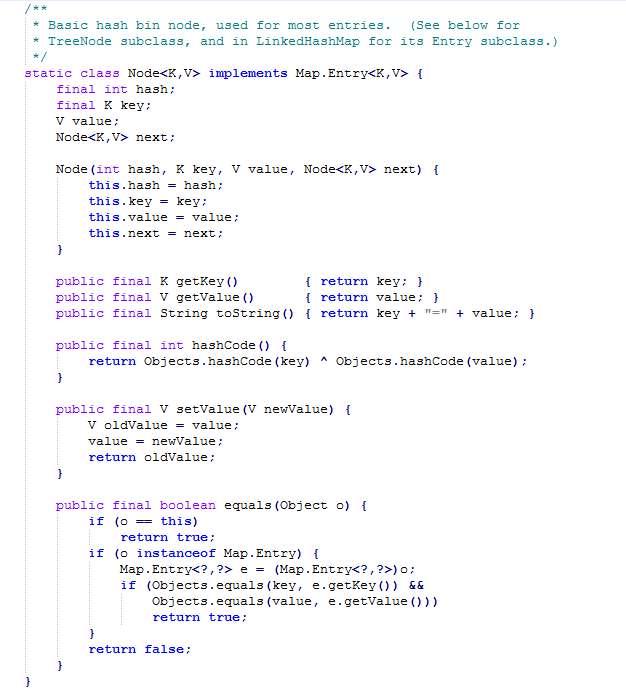
transient Node<K,V>[] table;
下图为HashMap的数据结构:
2、HashMap的工作原理
(1)HashMap底层是hash数组和单向链表实现,数组中的每个元素都是链表,由Node内部类(实现Map.Entry<K,V>接口)实现,HashMap通过put&get方法存储和获取
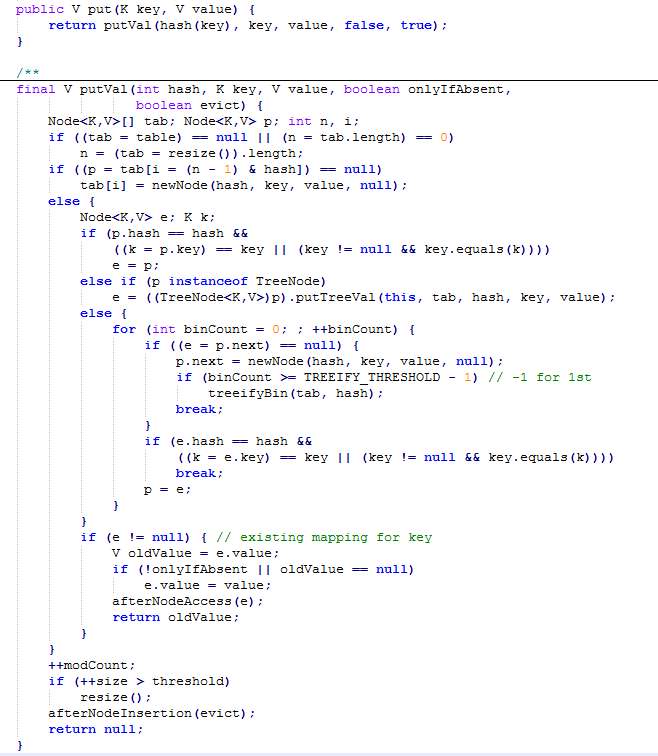
(2)存储对象时,将K/V键值传给put方法:
-
调用hash(K)方法计算K的hash值,然后结合数组长度,计算得到数组下标
-
调整数组大小(当容器中的元素个数大于capacity*loadfactor时,容器会进行扩容resize为2n)
-
如果K的hash值在HashMap中不存在,则执行插入,若存在,则发生hash碰撞;如果K的hash值在HashMap中存在,且它们两者equals返回true(说明同一个key),则更新键值对;如果K的hash值在HashMap中存在,且它们两者equals返回false,则插入链表的尾部(JDK8使用尾插法,JDK7使用头插法)或者红黑树中(JDK8使用红黑树,当碰撞导致链表大于TREEIFY_THRESHOLD=8时,就会把链表转换为红黑树)
(3)获取对象时,将K传给get方法

-
调用hash(K)方法计算K的hash值,从而获得该键值所在链表的数组下标
-
顺序遍历链表,equals方法查找相同Node链表中K值对应的V值
3、当两个对象的hashcode相同会怎样?
hashcode是定位数组位置的,即存储位置;equals是定性的,比较两者是否相等。
因为hashcode相同,不一样就是相等的(equals方法比较相等),所以两个对象所在数组的下标相同,“碰撞”就因此发生。又因为HashMap是使用链表存储对象的,这个Node就会存储到相同的链表中。
4、JDK源码中HashMap的hash方法原理
下图为JDK8中的散列值优化函数,只做一次16位右移异或混合,与JDK7原理一样
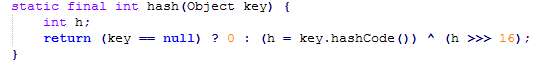
上面代码中h=key.hashcode()函数调用的是key键值类型自带的哈希函数,返回类型为int类型的散列值。如果直接拿散列值作为下标访问HashMap主数组的话,考虑到2进制32位带符号的int值范围为-2147583648到2147463648,前后加起来40亿的映射空间,即只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。【hash函数的目的应该是解决尽量少的hash碰撞,使得散列均匀些】
但是一个40亿的数组,内存是放不下的。HashMap扩容前的初始数组大小为16,因此散列值是无法直接拿来使用,必须对其做数组长度的取模运算,得到的余数才能用来访问数组下标。即为源码中的indexFor()函数来完成。

indexFor的代码也很简单,就是把散列值和数组长度做一个“与”运算

【问题】为什么HashMap的数组长度要取2的整次幂?因为这样(数组长度-1)正好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组的下标访问。以初始长度16位例,16-1=15,二进制表示为00000000 00000000 00000000 00001111。因此和某散列值做“与”运算时,结果为截取了散列值低4位的值作为数组下标。
但是这时候问题来了,就算是散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。更要命的是如果散列本身做的不好,分布上成等差数列的漏洞,恰好使得最后几个低位呈现规律性重复,就起不到减少hash碰撞的作用了。
这时候“扰动函数”的价值就体现出来了:
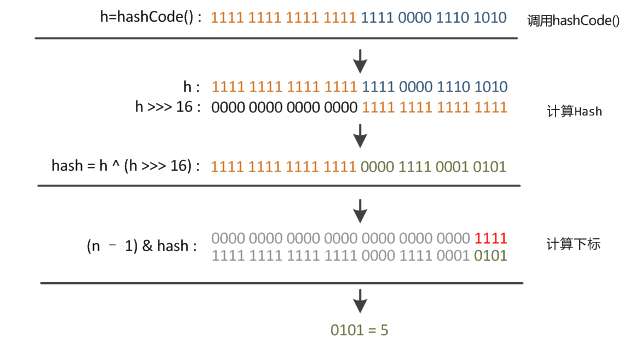
右移16位,正好是32bit的一半,自己的高半区和低半区做异或操作,就是为了【混合原始哈希码的高位和低位,以此来加大低位的随机性】。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也变相保留下来了。
5、为什么HashMap的数组长度要为2的n次幂?
与hash算法的操作以及计算key在HashMap数组的下标有关,hash函数中计算到的哈希值要与(数组长度-1)做“与”操作,如果数组的长度为2的n次幂,则length-1刚好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组的下标访问。以初始长度16位例,16-1=15,二进制表示为00000000 00000000 00000000 00001111。因此和某散列值做“与”运算时,结果为截取了散列值低4位的值作为数组下标。
6、HashMap的table的容量如何确定?loadFactor是什么?该容量如何变化?
(1)table数组大小是由capacity这个参数决定的,默认为16,也可以构造时传入,最大限制为1«30

(2)loadFactor是装载因子,主要目的是用来确认table数组是否需要动态扩容,默认值为0.75,比如table数组大小为16,装载因子为0.75时,threshold就是12,当table的实际大小超过12时,table就需要动态扩容。

put存储时,会一个数组大小的判断,若大于threshold,则执行扩容resize()

(3)扩容时,调用resize()方法,将table长度变为原来的两倍(注意是table长度,不是threshold)